












原文标题:Dual Contrast-Driven Deep Multi-View Clustering
原文作者:崔金荣, 李雨霆, 黄翰* , 文杰*
原文期刊:IEEE Transactions on Image Processing(CCF-A类Top期刊)
原文链接:https://ieeexplore.ieee.org/document/10648641
原文发表时间:2024年8月
摘要
多视图聚类(Multi-view Clustering, MVC)方法利用来自不同视角的模态信息,为无监督学习提供更强的表达能力。然而现有方法往往难以同时满足“类间判别性强”和“类内结构紧凑”的聚类友好结构需求,最终导致聚类性能不理想。
针对这一问题,华南农业大学、华南理工大学和哈尔滨工业大学(深圳)研究团队联合提出了一种双对比驱动的深度多视图聚类方法(Dual Contrast-Driven Deep Multi-View Clustering, DCMVC),通过引入类间对比的簇扩散机制(Dynamic Cluster Diffusion, DCD)和类内对比的可靠邻居正向对齐机制(Reliable Neighbor-Guided Positive Alignment, RNGPA),同时优化类间分离性和类内紧凑性。
该方法在多个典型多视图数据集上进行了验证,实验结果表明:所提DCMVC方法在聚类准确率(ACC)、归一互信息(NMI)和F-score等指标上均显著优于现有主流方法。相关源代码与实验配置已开源,访问地址为:
GitHub:https://github.com/tweety1028/DCMVC
一、研究背景
在各类数据采集和表示方式高度多样的背景下,多视图聚类成为高维异构数据无监督建模的重要方向。相比单视图,多视图聚类具有以下优势:
1)提高了聚类准确性:多视图数据融合捕获了更完整的样本特征信息,显著提升了聚类精度;
2)特征互补性增强:不同视图间的互补信息能够弥补单一视图的特征缺失,提高模型鲁棒性;
3)数据噪声鲁棒性:多视图协同分析可有效降低单一视图噪声对聚类结果的干扰,提升系统稳定性。
二、研究现状与现有问题
在基于表征学习的MVC家族领域,现有的方法主要分为两类:基于浅表征学习的方法和基于深度表征学习的方法。
1)基于浅层表征学习:依赖于传统的机器学习技术,如核方法、子空间学习和图学习等,这些方法在处理高维数据和非线性关系时能力有限,难以捕捉数据的深层次结构信息。
2)基于深度表征学习:利用深度学习模型提取高级特征表征,虽然在特征提取方面具有显著优势,但现有方法在对比学习中存在虚假负样本对的问题,影响了聚类性能。
虽然相比单一视角,MVC通过整合来自不同视角的数据表征,在保持原始信息多样性的同时显著提升了聚类的稳定性与准确率。然而,当前主流MVC方法存在三个关键短板:
1)忽视类别结构:多数方法只关注视图间一致性,忽略了“同类聚合、异类分离”的聚类结构要求,导致表征不适用于直接聚类。
2)伪负样本干扰:对比学习中常把“非同一视图”样本视为负样本,容易误伤本属同一类别的样本,破坏类内紧凑性。
3)融合方式粗糙:许多方法采用拼接或平均策略融合多视图特征,未考虑各视图贡献差异,导致信息利用不充分甚至失衡。
三、主要内容
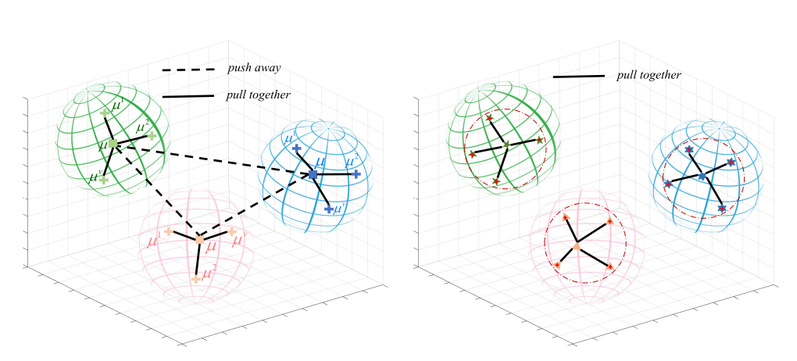
本文提出双重对比机制驱动的深度多视图聚类网络DCMVC,系统解决现有方法在“类间分离不足”、“类内聚合不强”、“伪负样本干扰严重”以及“特征融合粗糙”等问题。DCMVC整体框架图如图1所示。
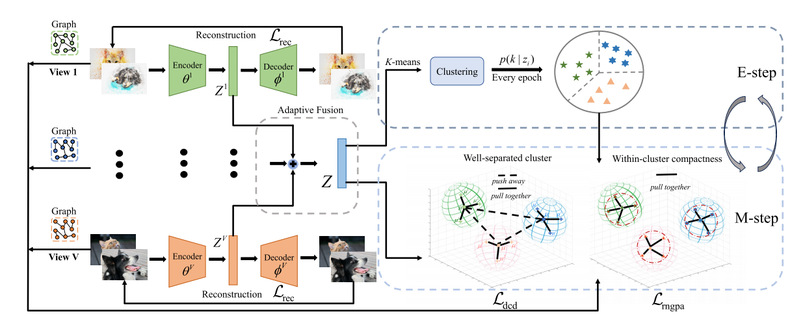
图1 DCMVC整体框架图
整体方法由四个关键组件组成:
1)视图特定自动编码器:提取高阶视图特征,保持视图特异性;
2)自适应特征融合模块(AFF):基于可学习权重融合多视图表征,提升信息整合质量;
3)动态簇扩散模块(DCD):引入簇中心对比损失,增强类间分离性;
4)可靠邻居引导正样本对齐模块(RNGPA):结合伪标签与邻居结构,消除伪负样本,增强类内紧凑性。
实验结果:
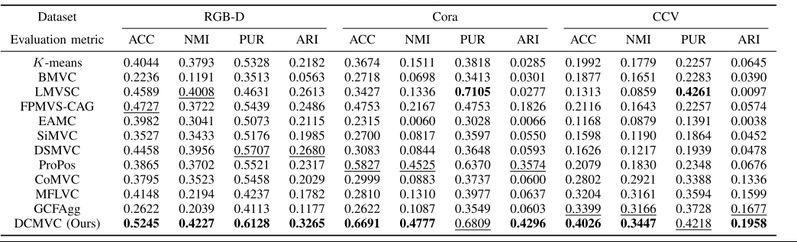
(1)性能对比
如表1所示,DCMVC在多个数据集上显著优于现有方法:
表1 RGB-D、CORA和CCV数据集的聚类结果
(2)特征可视化
如图2所示,训练后的特征空间呈现出清晰的簇结构,类间分离明显,类内紧凑。
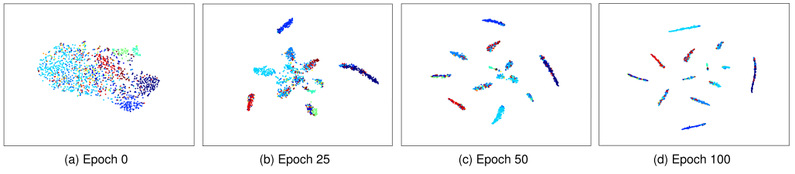
图2 双重对比学习过程中RGB-D中特征的可视化
(3)消融实验
如表2所示,移除关键模块会导致性能显著下降:
· 移除DCD:ALOI数据集ACC下降5.25%。
· 移除RNGPA:CCV数据集ACC下降15.38%。
表2 消融研究

四、研究创新点
1)提出类间对比与类内对比联合建模机制,同时优化聚类结构的分离性与紧凑性;
2)构建动态簇扩散模块,在类级别建模簇结构对比,提升判别能力;
3)设计邻居引导正对齐模块,避免伪负样本干扰,增强类内一致性;
4)引入视图自适应融合策略,捕捉不同视图的重要性差异;
5)提出可复现、端到端训练流程,源代码与数据已公开,具备实用性和可比性。
参考文献
[1] Jinrong Cui(崔金荣), Yuting Li, Han Huang* , Jie Wen*; Dual Contrast-Driven Deep Multi-View Clustering,IEEE Transactions on Image Processing,2024. (TIP,中科院一区,CCF-A类Top期刊,IF:12.1).
[2] Cheng Huang, Wenzhe Liu, Jinghua Wang, Jinrong Cui*(崔金荣), Jie Wen*; Dual-Driven Cross-Modal Contrastive Hashing Retrieval Networks Via Structure Feature and Semantic Information, Information Fusion, 123(2025)103252.
[3] ;Jinrong Cui(崔金荣), Yulu Fu, Cheng Huang, Jie Wen*; Low-rank graph completion-based incomplete multiview clustering. IEEE Transactions on neural networks and learning systems, 2022-11-01. (TNNLS,中科院一区,IF:14.255).
[4] Jinrong Cui(崔金荣), Xiaohuang Wu, Haitao Zhang, Chongjie Dong, and Jie Wen*. Structure-guided deep multi-view clustering. Information Fusion (2025): 103461.
[5] Cheng Huang, Jinrong Cui*(崔金荣), Yulu Fu, Dong Huang(黄栋), Lusi Li; Incomplete multi-view clustering network via nonlinear manifold embedding and probability-induced loss. Neural Networks, 2023,163:233-243.(中科院一区,IF:8.4)
[6] Jinrong Cui(崔金荣),Zhipeng He, Qiong Huang(黄琼), Jie Wen*, Structure-aware constructive hashing for unsupervised cross-modal retrieval. Neural Networks, 2024.(中科院一区,IF:8.4)
[7] Jinrong Cui(崔金荣),Yazi Xie, Qiong Huang*, Jie Wen*, Deep dual incomplete multi-view multi-label classification via label semantic-guided constructive learning. Neural Networks. 2024. (中科院一区,IF:8.4)
[8] Jinrong Cui(崔金荣), Yuting Li, Yulu Fu, Jie Wen*(文杰), Multi-view Self-Expressive Subspace Clustering Network, ACM MM 2023. MM’23: Proceedings of the 31st ACM International Conference on Multimedia, Oct 2023, Pages 417-425. (ACM MM2023,CCF-A类会议).
[9] 崔金荣,黄诚,改进的自步深度不完备多视图聚类,数据采集与处理,2022-09-15.(北大中文核心期刊)

评论 0