












练习1:制作文字云
step 1: 获得文本。本例的歌词文本见页面底部的附件: "分词素材"。
step 2: 分词。在线分词网站:http://www.78901.net/participle/
step 3: wordart制作文字云。https://wordart.com/
-------------------------------------------------------------------------------------------
英文分词:
string.split()
words=nltk.corpus.gutenberg.words('austen-emma.txt')
略
----------------------------------------------------------------------
中文分词
用的工具是Python里面的中文JIEBA分词工具。
安装jieba
pip install jieba
先进入anaconda的Prompt界面如下图:

jieba的教程:https://www.cnblogs.com/jiayongji/p/7119065.html
https://blog.csdn.net/qq_27882113/article/details/78126952?locationNum=4&fps=1
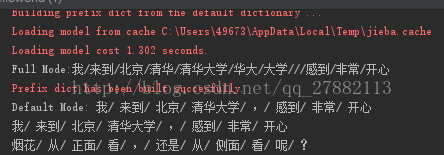
import jieba
seg_list = jieba.cut("我来到北京清华大学,感到非常开心", cut_all=True)
print("Full Mode:"+"/".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学,感到非常开心", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("我来到北京清华大学,感到非常开心")
print("/ ".join(seg_list)) # 默认精确模式
seg_list = jieba.cut_for_search("烟花从正面看,还是从侧面看呢?") # 搜索引擎模式
print("/ ".join(seg_list))
注:Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
seq = ["C", "h", "i", "n", "a"] # 字符串序列
print ("/".join( seq ))
print ("-*-".join( seq ))
输出结果:
C/h/i/n/a
C-*-h-*-i-*-n-*-a
练习2:将
"北京故宫是中国明清两代的皇家宫殿,旧称为紫禁城,位于北京中轴线的中心,是中国古代宫廷建筑之精华。北京故宫以三大殿为中心,占地面积72万平方米,建筑面积约15万平方米,有大小宫殿七十多座,房屋九千余间。是世界上现存规模最大、保存最为完整的木质结构古建筑之一。"
分词。并显示。

评论 0