








KDD (ACM SIGKDD Conference on Knowledge Discovery and Data Mining ) 是机器学习、人工智能与大数据分析领域顶级国际会议之一,与ICML、NeurIPS、CVPR 并称为人工智能方向的顶级会议。KDD 2025将于8月3日—8月7日在加拿大多伦多举行。PKU-DAIR实验室论文《LLMs are Noisy Oracles! LLM-based Noise-aware Graph Active Learning for Node Classification》被KDD 2025录用。
LLMs are Noisy Oracles! LLM-based Noise-aware Graph Active Learning for Node Classification
作者:Zeang Sheng, Weiyang Guo, Yingxia Shao, Wentao Zhang, Bin Cui
Github链接:https://github.com/PKU-DAIR/Noisy_LLM_Oracle
一、问题背景与动机
图神经网络(Graph Neural Networks, GNNs)因其出色的邻域信息捕捉能力,被广泛应用于节点分类、链接预测和药物发现等图学习任务中。与其他深度学习模型类似,GNN需要依赖充足的高质量标注数据进行训练,才能在下游任务中表现优异。然而,图结构数据中样本间复杂的连接关系使得人工标注的难度远高于图像或文本数据,导致标注成本高昂。例如,主流基准大规模图数据集OGB[1]中的ogbn-papers100M仅有约1%的节点被标注。
近年来,大语言模型(Large Language Models, LLMs)在文本任务中展现的零样本能力引发了广泛关注。已有研究[2]尝试将图数据转化为文本形式后利用LLM进行图学习任务,尽管其性能尚未超越专有GNN模型,但展现了良好的泛化能力。基于此,一个近期工作LLM-GNN[3]提出用LLM替代人工标注以低成本缓解数据稀缺问题。该方案通过后置过滤(Post Filtering, PS)剔除LLM不确定的标注,并采用基于均匀分布假设的噪声可感图主动学习算法RIM [4]处理标注噪声。
本文通过实验分析发现,同一个LLM在不同数据集上的标注噪声分布非常复杂且和具体数据集特征有关,因此LLM-GNN采用的均匀分布假设存在局限性。
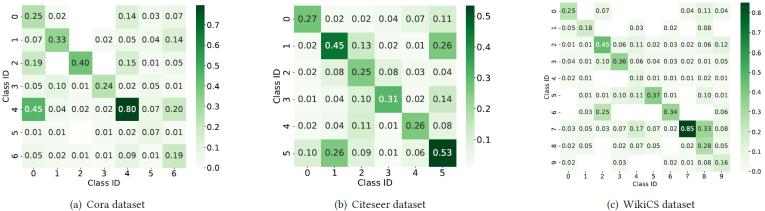
图1. LLM在不同数据集上的标注噪声分布
建模LLM标注噪声分布的难点在于双重感知需求:1.数据集可感:实验分析表明,同一LLM在不同数据集上会呈现高度异质性的噪声分布。这种数据集依赖性要求噪声模型必须动态适配目标数据集的特性。2. LLM可感:不同LLM因架构和训练差异表现出独特的标注行为特征。现有研究证实,某些LLM擅长结构化关系推理但在实体分类中表现不稳定,而另一些则相反。因此,噪声模型需精准捕捉当前所用LLM的固有偏差。这一问题的根本矛盾在于:缺乏真实标签使得传统校准方法失效;简单假设(如均匀分布)无法兼容上述双重感知需求。这一矛盾催生了本文的核心研究问题——如何在没有真值监督的条件下,构建同时满足数据集可感与LLM可感的噪声分布估计算法。
二、DMA框架详解
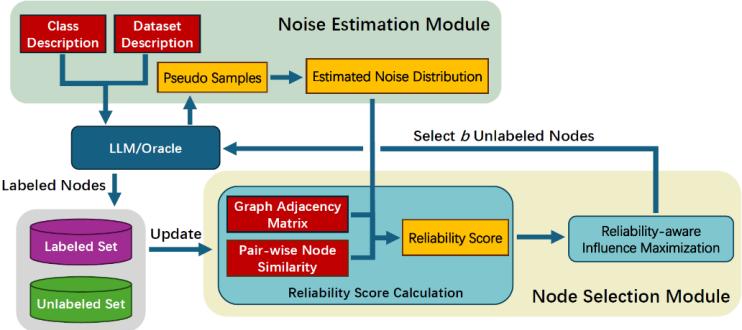
图2. DMA框架流程图
1. DMA流程概述:
DMA框架的工作流程概览如图2所示。我们构建DMA的目的是利用LLM对图结构数据进行标注。具体而言,DMA接收未标注的图和标注预算B作为输入,随后选择B个最具价值的节点进行标注,使得基于标注数据训练的GNN在下游图学习任务中表现最优。DMA由两个核心模块组成:噪声估计模块和节点选择模块。噪声估计模块负责以数据集可感和LLM可感的方式,显式估计大语言模型的标注噪声分布;节点选择模块则利用估计的噪声分布计算各节点的可靠性分数,并通过可靠性感知的影响力最大化策略筛选有价值节点。本节后续内容将详细阐述DMA的这两个模块
2. 噪声估计模块:
本文提出一种数据集可感与LLM可感的方法,用于显式估计大语言模型的标注噪声分布。我们的设计基于以下核心思想:表征相似的类别更易被相互混淆。基于该思想,噪声估计模块首先确定每个类别的表征,进而据此近似推导LLM的标注噪声分布。相应地,噪声估计模块包含两个连续步骤:1)伪样本生成,2)噪声分布计算。
1)伪样本生成:
本步骤旨在为数据集中的每个类别生成伪样本,其嵌入向量将作为对应类别的表征。这些伪样本由用于标注的LLM生成以确保与标注结果的一致性(示意图见图3)。具体实现时,我们为每个类别构建包含数据集描述和类别描述的提示词(Prompt),要求LLM生成最匹配目标类别的数据样本。这样一来,生成的伪样本能够反映基准LLM对数据集中各类别的理解,具有数据集适应性和LLM特异性。

图3. 伪样本生成示例
2)噪声分布计算:
本步骤利用前步生成的伪样本近似LLM的标注噪声分布。对于类别,我们从基准LLM获取其伪样本的嵌入向量作为该类别表征。随后计算所有类别对的余弦相似度矩阵:
随后通过行归一化(1-范数)得到标准化矩阵。根据“相似表征类别易混淆”的核心思想,该矩阵衡量了LLM将类别节点误标注为类别的概率。因此该矩阵即为DMA中估计的LLM标注噪声分布,该分布将用于节点选择模块中的节点可靠性评分计算。
3. 节点选择模块
我们为DMA中的节点选择模块设计了一个新的图主动学习算法,该算法基于现有研究RIM进行改进:RIM假设标注噪声服从均匀分布,并通过计算节点可靠性分数实现可靠节点选择。然而如图1所示,LLM的标注噪声分布与均匀分布相差甚远。因此,当采用LLM进行数据标注时,我们提出的节点选择算法进一步利用了噪声估计模块中估计的LLM噪声分布,从而实现更精确的可靠性分数计算。
RIM仅针对已标注节点更新影响力质量(Influence Quality),而对未标注节点则简单采用预设的标注准确度分数作为其影响力质量。与RIM不同,DMA的节点选择模块将已标注节点的影响力质量分数沿图中的边传递至全图所有节点,从而实现所有节点影响力质量的动态更新。这种方法能为未标注节点生成更具意义的影响力质量评估。DMA的更新过程在原理上与PageRank[5]分数计算具有相似性。DMA的节点选择模块的其余部分沿用了RIM的设计,该框架基于社交影响力最大化领域的经典研究[6]。其核心思想是:优先选择能够最大程度扩展已标注节点激活范围的未标注节点,图4给出了一个简略的伪代码流程,具体算法流程请参见论文。

图4. DMA中节点选择算法伪代码
三、实验结果
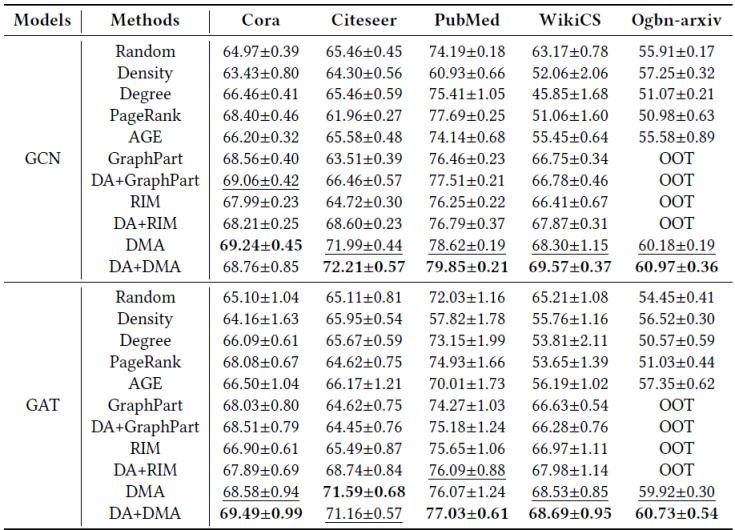
我们在五个常用的图数据集(Cora、Citeseer、PubMed、WikiCS、Ogbn-arxiv)上对DMA和基线方法在下游节点分类任务上的性能进行了对比分析。我们将节点选择预算B设置为20乘以各数据集的类别数量。基于每个方法生成的标注数据,我们训练了一个2层GCN/GAT模型。表1的评估结果表明,我们提出的DMA框架持续优于现有框架。表1还显示DMA的性能优势不受GNN模型选择的影响。由于DMA主要关注选择更可靠的节点,而LLM-GNN中的DA侧重降低LLM标注难度,二者的关注点正交,因此两者可以加以结合来进一步提升下游任务效果。表1中DA+DMA在多数配置下超越原始DMA的评估结果,验证了DA与DMA的成功融合。在大型Ogbn-arxiv数据集评估时,GraphPart[7]和RIM会出现"OOT(超时)"问题,而DMA能成功运行,展现了后者更高的可扩展性和运行效率。
表1. 节点分类任务上的性能对比,OOT代表超时(Out of Time)
为了验证DMA中噪声估计模块的有效性,我们对其预测的LLM标注噪声分布进行了可视化分析。图5分别展示了Cora和Citeseer数据集上的估计噪声分布,同时提供真实噪声分布作为对比基准。图5显示,估计结果基本反映了真实噪声分布的核心模式,这一现象解释了表1中DMA优于基线模型的性能表现。然而,估计分布与真实分布之间仍存在差异:例如在Cora数据集上,噪声估计模块认为第5类节点的错误标注概率为0.29,而其真实误标概率仅为0.07。这些偏差表明,未来需要进一步改进LLM标注噪声分布的估计精度。
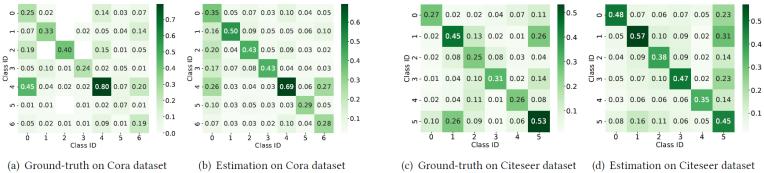
图5. 估算的噪声分布与真实的噪声分布对比
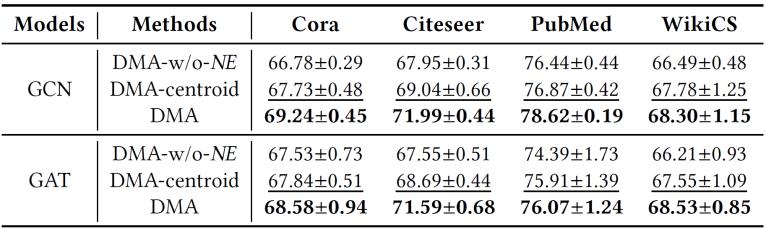
我们提出的DMA框架最核心的贡献在于:其噪声估计模块以数据集可感和LLM可感的方式,显式建模了LLM的标注噪声分布。为验证该模块是否如预期提升了最终性能,我们设计了以下实验:定义两种DMA变体——1)"DMA-w/o-NE":将噪声估计模块中的预测噪声分布替换为均匀分布,通过将均匀噪声率从0.1到0.5网格搜索后取最高测试精度作为最终性能;2)"DMA-centroid":采用节点特征经K-Means聚类生成的质心嵌入作为类别表示(假设该变体可利用真实标签对齐质心与真实类别以保证可行性)。表2的实验结果表明:完整版DMA在所有评估配置下均优于两种变体。DMA相对DMA-w/o-NE的性能优势,证实了噪声估计模块预测标注噪声分布的有效性;而DMA相对DMA-centroid的优越性,则源于其与LLM对数据集认知的更好对齐,这凸显了以数据集可感和LLM可感方式建模噪声分布的重要性。
表2. 噪声估计模块的消融实验
我们对比了DMA与GraphPart、RIM在节点选择阶段的时间和内存消耗。表2展示了在五个真实图数据集的评估结果。实验结果表明DMA在时间和内存开销上显著低于GraphPart、RIM等强基线框架,尤其在大规模数据集上优势明显。DMA的运行时性能优势源于我们采用的三项深度优化策略:1)使用C++实现节点选择操作,并采用OpenMP并行计算各节点可靠度影响值;2)手动构建并访问CSR格式的稀疏邻接矩阵,避免直接操作稠密矩阵;3)为每个线程维护小型缓存,预读取并存储线程专属的稠密邻接矩阵以减少冗余内存访问。
表3. 节点选择模块的开销对比

四、总结
现有工作通过采用大型语言模型(LLM)作为标注工具,实现了低成本的图主动学习。尽管已观察到LLM的标注存在噪声,现有工作仍简单假设其噪声服从均匀分布。然而,本文通过实验分析发现,LLM的标注噪声非常复杂且与数据集具体特征相关。基于分析结果,我们提出了一种新型噪声可感图主动学习框架DMA。该框架包含两个核心模块:1)噪声估计模块通过LLM生成的伪样本,以数据集和LLM双重可感的方式估算标注噪声分布;2)节点选择模块利用估计的噪声分布衡量节点可靠性,并选择能最大化可靠影响力的节点。在五个公开文本属性图数据集上的评估结果表明,DMA性能始终优于所有基线方法。
参考文献
[1] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open Graph Benchmark: Datasets for Machine Learning on Graphs. arXiv preprint arXiv:2005.00687 (2020).
[2] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500.
[3] Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. 2024. “Label-free Node Classification on Graphs with Large Language Models (LLMs)”. In The Twelfth International Conference on Learning Representations.
[4] Wentao Zhang, Yexin Wang, Zhenbang You, Meng Cao, Ping Huang, Jiulong Shan, Zhi Yang, and Bin Cui. 2021. “Rim: Reliable influence-based active learning on graphs”. Advances in Neural Information Processing Systems 34 (2021), 27978–27990.
[5] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. “The PageRank citation ranking: Bringing order to the web”. Technical Report. Stanford infolab.
[6] David Kempe, Jon Kleinberg, and Éva Tardos. 2003. “Maximizing the spread of influence through a social network”. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 137–146.
[7] Jiaqi Ma, Ziqiao Ma, Joyce Chai, and Qiaozhu Mei. 2023. “Partition-Based Active Learning for Graph Neural Networks”. Transactions on Machine Learning Research (2023).
实验室简介
北京大学数据与智能实验室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括CCF优博、ACM中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。PKU-DAIR实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。


评论 0